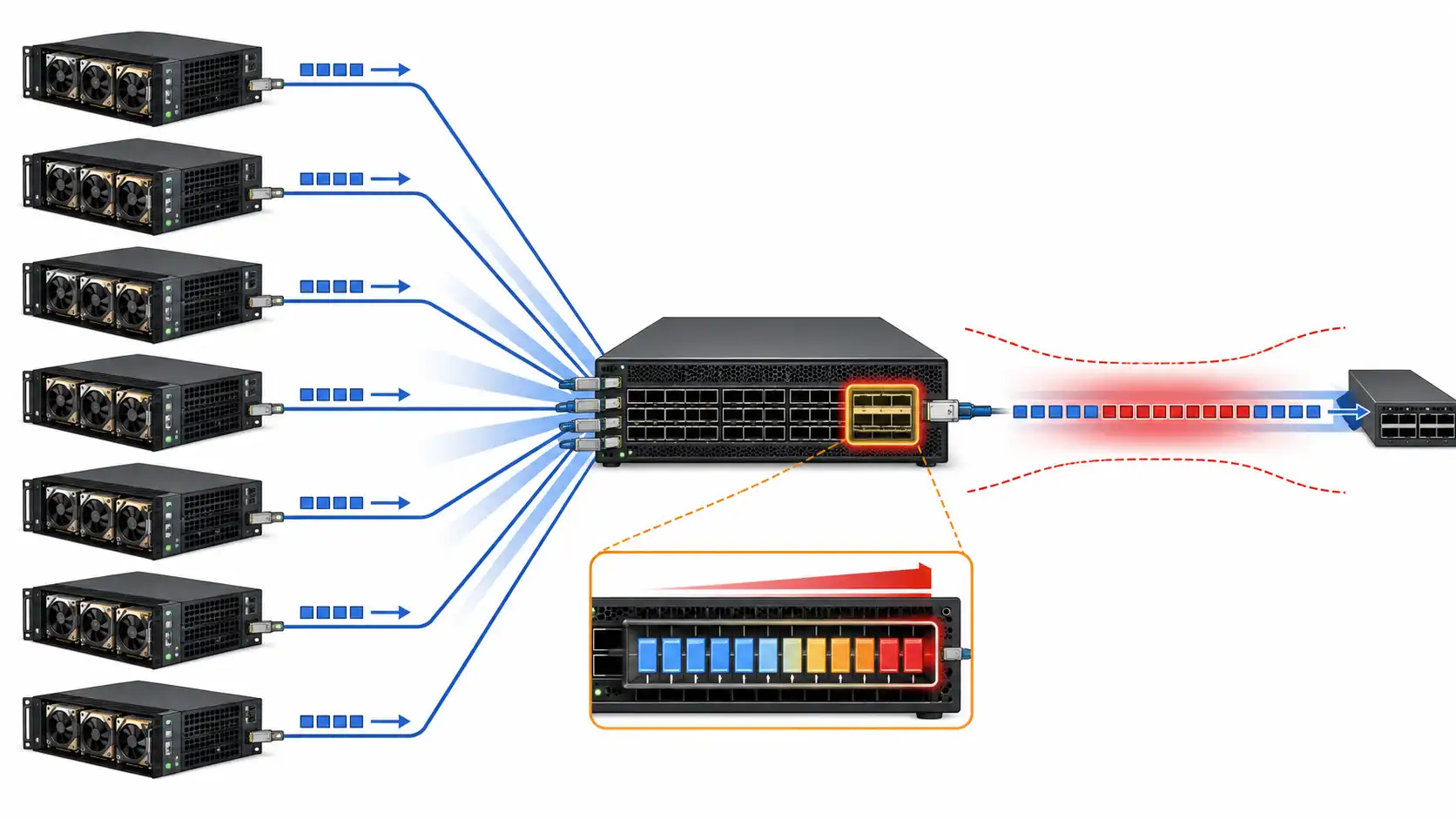
Switch buffers are small pools of memory inside a network switch that hold packets for a moment when traffic arrives faster than a port can send it. On a quiet enterprise LAN, that sounds like a hardware footnote. Inside an AI training cluster or a dense cloud fabric, the same few megabytes of memory can decide whether a distributed job finishes on time or stalls waiting on a single congested link.
The core idea is simple, but it trips up a lot of buying decisions: buffers are valuable because they absorb bursts, yet more buffer is not automatically better. The right design depends on your traffic pattern, how sensitive the workload is to latency or loss, which congestion-control method you run, and how the switch spreads buffer memory across ports and queues. A switch with a very large buffer can still perform worse than a smaller one if that memory hides congestion instead of draining it.
This guide is written from the patterns commonly seen in RoCEv2 fabrics and high-density leaf-spine deployments. It explains what switch buffers actually do, why AI and GPU traffic stresses them differently, how buffer choices affect latency and packet loss, and what to test before you commit to a switch.
What Are Switch Buffers?
A switch buffer is temporary packet memory. When several packets need to leave through the same port at the same instant, the switch cannot transmit them all at once, so it queues the extras and forwards them as the output port frees up.
This queuing happens during a handful of predictable moments:
- Many-to-one (incast) traffic, where multiple senders target the same receiver or uplink
- Microbursts, the short and intense spikes that last microseconds to a few milliseconds
- Interface speed mismatches, such as a 400G port feeding a slower downstream link
- Oversubscribed links and synchronized bursts arriving from many sources at once
- Congestion on one specific output queue or traffic class
Without enough usable buffer, the switch drops packets. With too much occupied buffer, packets sit in line and latency climbs. Good buffer design lives in the tension between those two failures: absorbing real bursts without turning the queue into a holding pen.
Why AI and GPU Traffic Stresses Switch Buffers Differently
AI workloads do not look like web or office traffic. GPU clusters generate enormous east-west traffic between servers, and during distributed training the communication is often synchronized: many accelerators exchange data at the same moment, in the same direction, on the same fabric.
Collective operations make this worse. An all-reduce step, parameter synchronization, or a gradient exchange can collapse into a many-to-one or many-to-many burst that slams a set of egress queues within microseconds. Because the bursts are brief and tightly correlated, they are easy to miss with coarse monitoring. For instance, a link can read only around 40% average utilization in a one-second or five-minute polling window while still hitting line rate for milliseconds at a time, which is long enough to fill a queue, mark ECN, or trigger a PFC pause.
The reason this matters so much in AI fabrics is the dependency structure of the job. Distributed training tends to move at the speed of its slowest flow. When one GPU node waits on delayed traffic, the rest of the cluster often idles with it, and expensive accelerators burn time waiting on the network rather than computing. A buffer event that would be invisible on a web tier can directly extend job completion time here.
That east-west fabric is also why physical-layer choices ride alongside buffer behavior. High-density GPU backends are typically wired with high-density MTP/MPO trunk cabling between leaf and spine, and the link speed is set by the optics you choose, increasingly 400G and 800G modules such as QSFP-DD. The faster and more oversubscribed those links are, the more work the switch's buffer and congestion settings have to do during a synchronized burst.

How Switch Buffers Affect Latency, Packet Loss, and Throughput
Buffers shape performance in three connected ways.
Too little buffer causes packet loss
When a burst exceeds the available buffer, the switch tail-drops packets. In TCP-based traffic that triggers retransmissions and cuts effective throughput. In storage and AI traffic it can inflate job completion time and make performance erratic. The trap is that average bandwidth often looks fine: in an incast event, several senders hit the same egress queue at nearly the same instant, and the queue overflows even though the minute-by-minute graph looks calm.
Too much queued traffic increases latency
A large buffer is not a free safety margin. If packets sit in a deep queue, they accumulate queuing delay, and the network slides into bufferbloat, where drops are rare but latency is high and unpredictable. This failure mode was documented in detail by Gettys and Nichols in ACM Queue, and it is exactly the wrong outcome for latency-sensitive GPU backends, where predictable low latency matters more than hiding congestion inside memory.
Poor buffer allocation creates unfairness
Total buffer size hides the more important question: how the switch divides that memory across ports, queues, and traffic classes. A switch can carry plenty of aggregate buffer and still behave badly if one port or class drains the shared pool and starves the rest. In AI and storage environments, that unfairness slows the whole job, because the slowest flow sets the finish time.

Shared Buffer vs Dedicated Buffer vs Deep Buffer
When you compare data center switches, the buffer architecture matters more than the headline capacity number.
Shared buffer
A shared buffer is a common memory pool that ports and queues draw from on demand. Because unused memory in a quiet area can be lent to wherever congestion appears, shared buffers absorb bursts well in data centers, where a port that is idle one moment may take a burst the next. Their weakness is that they rely on good allocation logic to stop one hot queue from eating the pool.
Dedicated buffer
A dedicated buffer is reserved for a specific port, queue, or traffic class. It improves isolation, since one congested class is less able to consume everything, but over-reserving wastes capacity, because memory locked to a quiet port is not available where the burst actually lands.
Deep buffer
A deep-buffer switch carries much larger buffering, designed for big bursts, long-distance links, or persistent speed mismatches. Deep buffers earn their place in some WAN, routing, and aggregation roles, often paired with single-mode fiber for longer-distance links, but they are frequently the wrong default for a low-latency GPU backend, where they tend to mask congestion and add delay. For latency-sensitive fabrics, predictable forwarding usually beats raw buffer depth.
Quick comparison
| Buffer type | Strength | Main risk | Best fit |
|---|---|---|---|
| Shared | Flexible burst absorption | Needs solid allocation logic | Dynamic data center traffic |
| Dedicated | Strong isolation between classes | Wasted capacity if over-reserved | Traffic classes that must be protected |
| Deep | Absorbs very large bursts | Higher queuing latency | WAN, routing, special aggregation |
Switch Buffers and RoCEv2 Congestion Control: ECN and PFC
Most AI Ethernet fabrics run RoCEv2 for low-latency, high-throughput RDMA. In these networks, buffers and congestion control are inseparable: the buffer thresholds you set determine when ECN marks and when PFC fires.
ECN should signal congestion early
Explicit Congestion Notification (ECN), defined in RFC 3168, lets a switch mark packets as congestion builds instead of dropping them. The receiver echoes that signal back so the sender slows down before the queue overflows. In RoCEv2 fabrics the marking threshold is a tuning decision with real consequences: mark too late and the queue is already deep when sources react; mark too early and you throttle throughput you did not need to give up.
PFC should be the safety net, not the first response
Priority-based Flow Control (PFC), standardized as IEEE 802.1Qbb, pauses traffic on a priority class to prevent loss on lossless queues. It is essential, but it is a blunt instrument. Lean on it too often and it spreads congestion upstream, creating pause storms and head-of-line blocking that punish flows that were never the cause. The healthier pattern is well established: in Microsoft's large-scale RDMA work that introduced DCQCN, rate-based congestion control driven by ECN handles the routine events while PFC stays in reserve as the last line of defense, and that paper also gives concrete guidance on tuning switch buffer thresholds.
Buffer thresholds must match the workload
Thresholds copied from a reference design rarely survive contact with real traffic. AI training, inference, storage, and mixed cloud workloads burst differently, and the right ECN/PFC settings depend on burstiness, link speed, oversubscription ratio, queue design, and how much the workload tolerates latency versus loss. Treat the vendor defaults as a starting point, then tune against your own traffic.
Diagnosing Buffer-Related Problems: Symptoms, Causes, and Metrics
When application performance drops but the dashboards look green, buffer pressure is a common hidden cause. A useful first move is to read the telemetry in order of cause and effect rather than staring at link utilization. The table below maps symptoms to likely buffer issues and the metric that confirms them.
| Symptom | Likely buffer-related cause | Metric to check first |
|---|---|---|
| Retransmissions with normal average utilization | Microburst tail drops on an egress queue | Queue occupancy peaks, tail and output drops |
| Latency spikes with few or no drops | Over-deep queue / bufferbloat | Latency percentiles (p99), queue depth |
| Throughput collapses under many-to-one | Incast overflowing a shared pool | Drops during incast, per-queue occupancy |
| Periodic stalls across the cluster | PFC pause storms spreading upstream | PFC pause frames and pause duration |
| One slow flow drags the whole job | Unfair buffer sharing between classes | Per-priority occupancy, hot-queue counters |
| GPUs idle waiting on the network | Congestion extending collective operations | ECN mark rate, flow completion time, GPU utilization |
Read top to bottom, the natural diagnostic chain is queue depth, then ECN marks, then tail drops, then PFC pause frames, then flow completion time, then GPU utilization. If the network metrics are clean but jobs are still slow, the problem is probably upstream of the fabric rather than inside the switch buffer.
Lab tests worth running, and what "pass" looks like
Before deploying into an AI or high-performance fabric, test with traffic that resembles your real workload, and define a pass criterion for each test rather than just watching for line rate.
- Many-to-one incast: ramp the fan-in ratio; pass means no tail drops and bounded p99 latency at your target oversubscription.
- Many-to-many, all-reduce style: drive synchronized bursts; pass means fair completion times across flows with no single straggler.
- Mixed short- and long-flow: run elephant and mouse flows together; pass means short flows keep low latency while long flows still fill the link.
- RoCEv2 congestion with ECN/PFC validation: confirm ECN marks before PFC pauses; pass means ECN does the work and PFC rarely triggers.
- Oversubscription and failure reconvergence: drop a link mid-burst; pass means graceful rerouting without a drop or a latency cliff.
The goal is not to prove line-rate throughput on an idle switch. It is to see how the switch behaves when traffic turns bursty, synchronized, and unfair, which is the only state that matters in production. When you are planning the cabling and connectors to support those tests at scale, an engineering comparison of MTP and MPO options is a useful companion.
Deep-Buffer or Low-Latency Switch?
There is no single best switch, only the best fit for a given fabric. Use the table below to narrow the choice quickly, then validate it with the lab tests above.
| If your fabric is | Prioritize | Buffer leaning |
|---|---|---|
| AI GPU backend (synchronized bursts, latency-critical) | Low latency, strong telemetry, ECN/PFC tuning | Low-latency, shared with good allocation |
| Storage / lossless | Fairness, job completion time, latency under load | Moderate, with well-isolated classes |
| Mixed cloud (varied link speeds) | Flexible allocation, class isolation, visibility | Shared and flexible |
| WAN / long-distance aggregation | Absorbing large bursts and speed mismatch | Deep buffer (still checked against latency targets) |
Mixed cloud fabrics are the trickiest case, because they often combine higher-speed uplinks with slower access links. If you are mapping out those access speeds, a guide to 10GBASE-T and SFP+ 10GbE interfaces can help you plan where the speed transitions, and therefore the buffering pressure, will land.
FAQ
Q: Are bigger switch buffers always better?
A: No. Larger buffers reduce packet drops during bursts, but they also let packets queue longer, which raises latency and can cause bufferbloat. For latency-sensitive AI and storage fabrics, a moderate, well-managed buffer usually outperforms a very deep one. The best buffer is the one sized and allocated to absorb your real bursts without adding avoidable delay.
Q: What is the difference between shared buffer and dedicated buffer?
A: A shared buffer is a common pool that any port or queue can draw from when it needs it, which makes it efficient at absorbing unpredictable bursts. A dedicated buffer is reserved for a specific port, queue, or class, which improves isolation but can waste memory if the reserved space sits idle. Many data center switches use a hybrid of the two.
Q: Why do microbursts cause packet loss even when utilization looks low?
A: Standard monitoring averages traffic over seconds or minutes, so it smooths out spikes. A microburst can hit line rate for only a few milliseconds, filling an egress queue and forcing tail drops, while the averaged graph still shows the link as lightly loaded. You need millisecond-scale queue and drop telemetry to see these events.
Q: Do AI data centers need deep-buffer switches?
A: Not usually on the GPU backend. Deep buffers tend to mask congestion and add latency, which works against the predictable, low-latency forwarding that distributed training needs. Deep buffers are more appropriate for WAN, routing, or aggregation roles. For AI clusters, telemetry, fair allocation, and well-tuned ECN/PFC typically matter more than raw buffer depth.
Q: How do switch buffers affect RoCEv2 performance?
A: In RoCEv2, buffer thresholds decide when ECN marks packets and when PFC pauses a priority. Set well, ECN slows senders early and keeps queues shallow; set poorly, queues overflow or PFC triggers too often and spreads congestion. Tuning buffer thresholds to the workload is one of the most important steps in getting good RoCEv2 behavior.
Q: What buffer metrics should I monitor in production?
A: Watch queue occupancy, tail and output drops, ECN mark rate, and PFC pause frames and duration, then connect them to application signals such as flow completion time and, for AI fabrics, GPU utilization. If application performance is poor while average link utilization looks normal, hidden buffer pressure and microbursts are likely suspects.
Key Takeaways
Switch buffers play a decisive role in AI and data center network performance, but capacity alone does not tell you whether a switch is the right choice. A good buffer design absorbs realistic bursts, limits packet loss, keeps latency predictable, supports ECN and PFC signaling, and exposes enough telemetry to troubleshoot. For AI data centers, evaluate the buffer architecture together with congestion control, load balancing, queue management, and the behavior of your real workload, not as an isolated number on a spec sheet.
Before you commit, test the switch under incast, microburst, and congestion conditions, and watch how it shares memory when traffic turns unfair. The best buffer is not the largest one. It is the architecture that keeps your applications fast, fair, and predictable under real traffic.